
https://proceedings.mlr.press/v97/song19b.html
Introduction
先行研究の手法は、Loss CorrectionとSample Selectionが主流であるが、それぞれ以下のような欠点がある。
- Loss Correctionでは、遷移行列を特定する(特にclassにのみ依存しインスタンスに依存しないトいう仮定)のは無理ではないか。それによって、false correctionが発生してしまう。
- Sample Selectionでは、信頼できるサンプルのみ選ぶが、難しいサンプルを選ばなくなって結果的にロバストじゃなくなるという欠点を持つ。そして信頼できないサンプルを削除する中で実は信頼できるのに、のようなものを多く消してしまう。
この論文ではSELFIE(Selectively Refurbish Unclean Samples)という手法を開発。Loss CorrectionとSample Selectionの両方のメリットを集めたという。高い精度で正しいラベルに直せる、改修可能なサンプルを、Cleanなサンプルと同時に集めて、back propagationしてパラメタ更新につなげること。高い精度で直せるというのは、モデルがそれなりに正しくないといけないので、ここでもカリキュラム学習を用いて訓練が進むほどその割合を増やす、最終的にはすべてをカバーするようにしている。
Related Work
既存の手法の性質は以下の通り。

- Flexibility 特定のアーキテクチャに依存しないか
- No Pre-train 事前学習が不要か
- Heavy Noise 高いノイズ率でも性能を残せるか
- Full Exploration 訓練データのすべてを利用するか。
いつも通り自分の読む用のメモみたいな。
この手法はデータを全部利用する上で、高いノイズ率にも頑強である。
Robust Training via SELFIE
Overview
が真のラベルを持つデータセットで、であるとする。しかし、現実ではラベルがNoisyなデータのバッチをSGDなどでバッチごとに更新する。に所属するデータはであり、ラベルが間違っている可能性がある。
普通ならば、以下のようにSGDで勾配を更新する。
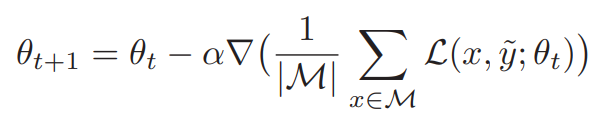
この論文では、をまず選ぶ。は完全に正しいラベルを持つデータセットでは修正可能のデータセットである。修正可能とは、back propagationによって、ラベルをもっと正しいと思われるものに修正するということ。つまり、に含まれているラベルは更新によって書き換えられていく。
なお、ここでである必要はない。たとえに入っていたとしても、誤っているかもしれないという考えである。この機構を考えたSGDの勾配更新の式は以下の通り。
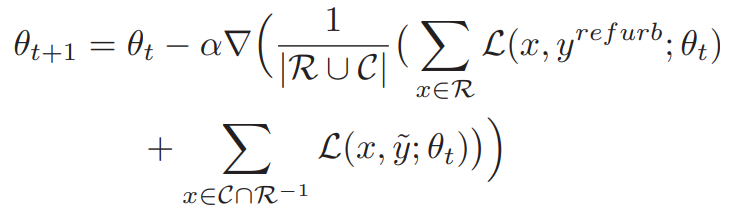
- そもそもに含まれていないバッチ内のサンプルは、更新に使用しない。
- すべてのに含まれているサンプルは、修正後のラベルでlossを計算しback propagationをする。ただし、で割る。
- はに相当する。そこに含まれているものは、正確だということなので、当初のラベルでlossを計算しback propagationする。
- それ以外のものはNoisyであるとして、lossの計算に寄与させない。
この手法の肝心なところは、をどのように選ぶかである。
についてはLossが低い順にサンプルをの割合で選んでいる。問題はどのようにを構築するか。
Main Concept: Selective Loss Correction
Noisyなデータに完全に適合する前に、Noisyなラベルに対してのgradientは今までの動きと矛盾した向きへ動くか、今までの通りに一貫するか。
改修可能は明確には以下のように定義されている。とする。
- はサンプルの、時刻においての(訓練した)分類器の予測ラベルである。
- は、時刻までのサンプルの予測結果の集合
- は、時刻までの予測結果をもとにした、サンプルがクラスである確率。
- 単純に、今までの予測したクラスである割合である。
- はエントロピーが取りうる最大値。のエントロピーをに収めているだけ。
- つまり以下の順番である。
- 今まで回の内にを予測した割合を計算する。
- それについて、エントロピーを計算する(非常に高いか低い場合は低くなり、ぼんやりだと高く出る)。
- それをで割ってに収めて正規化する。
- その正規化した値が一定値以下の場合、改修可能だとする。つまり、予測結果がほとんど決まっているということだから。
Loss Correction
対象のサンプルについて、Noisyなラベルを書き換えることがLoss Correctionである。書き換える先は、である。
- 各タイムステップごとの予測がほぼほぼ決まっているようなものをに入れている。
- それらに対して、最も所属する可能性が高いクラスを、書き換え後のクラスとしている。
- が高くてに入れられたサンプルは、そのまま新しいラベルはになる。
- が低くてに入れられたサンプルは、ほぼ確実にほかのラベルということなので、これも書き換えていいという扱い。
- 定義の通りだと、すでに十分に正しいラベルを持つサンプルも書き換え候補であり、書き換え先と後が同じであっても問題はない。
アルゴリズムの部分で詳しく書くが、各ミニバッチごとに、書き替えしたを全体的に蓄積させていく。から消すということはない。
Quick Analysis
最初には、信頼のおける一部のサンプルだけで学習をさせてから、徐々に学習するサンプルを増やすのが妥当である。
Algorithm

- 最初のWarm-upは普通にNoisyなラベルのままで訓練を行う。Memorization Effectによってそれなりの
- 学習率は調整してなさそう。SOTAの研究では学習率をわざと大きく学習することで、Noisyな部分を取り込まないようにすることができる。
- Warm-up過ぎたら、先ほど述べたようにとのものだけでlossを計算してbackwardする。
- その前に、先ほど述べた方法でを構築する。
- 最終的に全体的に書き換えたサンプルの集合を返す。次にいうRestartで使うから。
- Restartでは、この訓練が複数回行われることを意味している。
- 今までの訓練で選び出したをもとに、もう1回パラメタを初期化して再訓練すること。
- きれいになったはずの訓練データでもう1回訓練するので、より高い精度を期待できる。
Coteachingとの組み合わせ
ここにCoteachingの論文を読んで書く。
SELFIEはCoteachingとも組み合わせられる。Coteaching+SELFIEは以下のようなアルゴリズム。
- 2つのネットワークを同時に訓練する。
- 各ミニバッチで、2つのネットはそれぞれCleanな集合、書き換えた後のサンプルの集合を選び出す。
- ネットAはBに自分のCleanな集合、書き換えた後の集合を与えて、それをもとにBのパラメタを更新させる。ネットBも同様にAに与えて更新させる。
- Coteaching自体、訓練サンプルの選択バイアスを消すことに有効であるが、この性質は残ったまま。
Result
Pairwise Noise, Symmetric Noiseの両方において、SELFIEは高ノイズ環境に強いことがわかった!
実データセットにおいてのノイズも、SELFIEは改善している。
Co-teachingについては、Pairwise Noiseではいい性能が出なかった。なぜなら、labelミスされているサンプルのlossはそこまで大きくなかったのが問題。
しかし、同じCo-teachingでも、Symmetric Noiseではちゃんとlabelミスされているサンプルのロスはそれなりに大きかったのでこの手法は有効だった。
Restartによって、訓練に使用したサンプルの数はの蓄積によって、59.2%から90.2%まで劇的に上昇させた。時間はかかるが、再起動は間違いなく有効である。